
Machine learning (ML) APIs offer powerful capabilities for automating tasks like image recognition, text analysis, and speech processing. However, data preparation is crucial to ensuring high model accuracy and efficiency.
In this guide, we’ll walk through the steps to prepare data for ML APIs in Google Challenge Lab, covering data collection, cleaning, transformation, and integration with Google Cloud tools. Let’s get started!
Understanding ML APIs in Google Challenge Lab
What is Google Challenge Lab?
Google Challenge Lab is an interactive learning environment designed to help users develop hands-on experience with Google Cloud technologies. It provides real-world tasks that test users’ ability to implement machine learning (ML) models using Google Cloud services. A crucial part of any ML workflow in these labs is data preparation, which significantly impacts the performance and accuracy of models.
Why is Data Preparation Important?
Data preparation is the foundation of a successful machine learning project. Properly curated and cleaned data ensures that ML models receive accurate input, leading to better predictions and overall performance. Google Challenge Lab emphasizes data preparation as an essential step before deploying ML models.
Overview of Google Cloud ML APIs
Google Cloud offers a variety of ML APIs that help developers integrate AI capabilities into their applications. Each API is designed to handle specific types of data and solve distinct AI problems. Below are some of the most commonly used ML APIs:
Vision API
The Google Cloud Vision API allows developers to analyze images using machine learning. It can detect objects, faces, logos, and handwriting, as well as classify images into predefined categories.
Natural Language API
This API helps process and analyze text by understanding sentiment, extracting key phrases, and identifying entities. It is particularly useful for applications that require text analysis, such as chatbots and content categorization.
Speech-to-Text API
The Speech-to-Text API enables applications to convert spoken language into written text. It supports multiple languages and can be customized for domain-specific terms.
AutoML
AutoML provides a suite of ML services that allow users to train custom models without requiring deep knowledge of machine learning. It simplifies the process of creating high-quality models for tasks like image recognition, natural language processing, and structured data analysis.
Importance of Data Preparation for ML APIs
Data quality directly impacts the effectiveness of machine learning models. Preparing data correctly ensures that ML APIs produce accurate and meaningful results. Below are some key considerations when preparing data for Google Cloud ML APIs:
Impact of High-Quality Data on Model Accuracy
- Clean data: Remove duplicate, missing, or inconsistent data points.
- Balanced datasets: Ensure that different classes in classification tasks are well-represented.
- Proper labeling: Label training data accurately to help models learn patterns effectively.
Common Challenges in Preparing Data for ML Models
- Data inconsistencies: Variations in formatting, spelling, or missing values can reduce model efficiency.
- Bias in datasets: Poorly selected datasets may introduce bias, affecting the fairness of predictions.
- Scalability issues: Large datasets require optimized storage and processing techniques to ensure smooth execution.
Learn more: Demystifying the Large Language Model Architecture
Collecting and Importing Data
Choosing the Right Data Sources
- Data used for ML APIs can be structured (databases, CSV files) or unstructured (images, audio, text).
- Sources for data collection include:
- Public datasets: Kaggle, Google Dataset Search, and open government data.
- Google Cloud Storage (GCS): A scalable storage solution for uploading and managing large datasets.
- Real-time data streams: IoT sensors, APIs, or web scraping methods for continuously updating datasets.
Importing Data into Google Cloud
- Using Google Cloud Storage (GCS):
- Upload datasets via the Google Cloud Console, command-line interface (CLI), or API.
- Organize files in storage buckets for easy access.
- Uploading Data to BigQuery:
- BigQuery is a fully managed, serverless data warehouse that allows efficient querying of large datasets.
- Data can be imported via CSV files, JSON, or connected directly from Google Cloud Storage.
Ensuring Data Privacy and Compliance
- When handling sensitive data, ensure adherence to security best practices:
- Encrypt data at rest and in transit.
- Restrict access using IAM roles and permissions.
- Compliance considerations:
- GDPR: Ensures user data privacy for European customers.
- HIPAA: Required for handling healthcare-related data in the U.S.
- CCPA: Protects consumer data for California residents.
- Google Cloud provides built-in compliance tools to assist in data security and regulatory adherence.
By understanding and implementing proper data collection and preparation techniques, users can maximize the performance and effectiveness of Google Cloud’s ML APIs in the Challenge Lab environment.
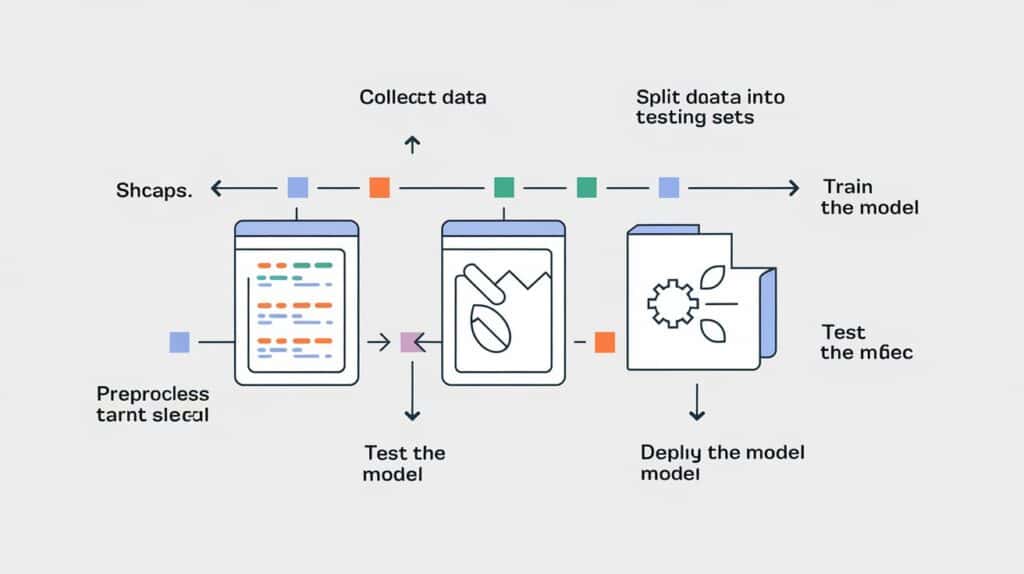
Data Cleaning and Preprocessing
Handling Missing and Duplicate Data
Missing and duplicate data can distort model performance. Strategies to handle this include:
- Removing duplicate entries from datasets.
- Imputation techniques like filling missing values with mean/median for numerical data.
- Using interpolation methods for time-series data.
Formatting and Normalizing Data
Machine learning models require data in a specific format. Preprocessing includes:
- Standardizing numerical values to avoid scale disparities.
- Tokenizing and stemming text for NLP tasks.
- Converting image files to standardized resolutions and formats (e.g., JPEG, PNG).
Feature Engineering for ML APIs
Feature engineering enhances data quality by extracting meaningful attributes:
- One-hot encoding categorical variables for NLP tasks.
- Tokenization and word embeddings for text processing.
- Image augmentation techniques (flipping, rotation) to improve model robustness.
Transforming and Preparing Data for ML Models
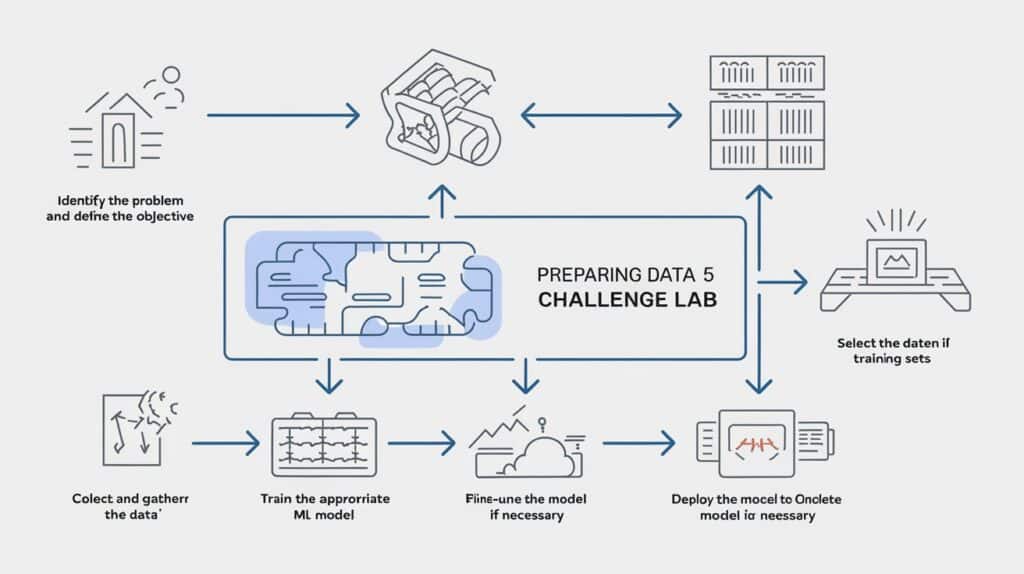
Data Labeling and Annotation
For supervised learning, labeled data is essential:
- Use Google Cloud Data Labeling Service for human-annotated datasets.
- Implement automated annotation tools for large datasets.
Splitting Data for Training, Validation, and Testing
Proper dataset partitioning ensures fair model evaluation:
- Training Set (70%) – Used for model training.
- Validation Set (15%) – Fine-tunes hyperparameters.
- Test Set (15%) – Evaluates final model performance.
Data Augmentation and Synthetic Data Generation
To improve model generalization, consider:
- Synthetic data generation using tools like TensorFlow Data Augmentation.
- Enhancing dataset diversity by adding noise or transformations to images, text, and speech data.
Integrating Data with Google Cloud ML APIs
Uploading Preprocessed Data to Google Cloud Storage
To make data accessible for ML APIs:
- Organize datasets into structured GCS buckets.
- Set appropriate IAM roles for access management.
Connecting Data to ML APIs
Once data is uploaded, integrate it with ML APIs:
- Use Google Cloud Vision API for image analysis.
- Connect text data with Natural Language API.
- Utilize AutoML for training custom models.
Running Test Predictions on ML APIs
To validate data and model effectiveness:
- Send API requests using Postman or Python scripts.
- Evaluate API response accuracy.
- Optimize results through fine-tuning model parameters.
Troubleshooting Common Data Preparation Issues
Addressing Data Imbalance in Training Sets
Imbalanced data can bias models. Solutions include:
- Oversampling the minority class.
- Undersampling the majority class.
- Using data augmentation to balance classes.
Fixing Formatting and Encoding Errors
To avoid errors:
- Convert files into compatible formats.
- Use UTF-8 encoding for text-based data.
Optimizing Data Processing Speed
Speed up large dataset processing with:
- Google Cloud Functions for automation.
- Parallel processing techniques in BigQuery.
Conclusion:
Prepare data for ML APIs on Google Challenge Lab is a crucial step in building high-performing AI applications. By following best practices for data collection, preprocessing, and integration, you can maximize the efficiency and accuracy of your ML models.
Want to improve your ML workflows? Explore Google Cloud’s AI training labs for hands-on experience with real-world datasets!
FAQs: Prepare data for ML APIs on Google Challenge Lab
Google Challenge Lab is a hands-on learning platform that helps users gain practical experience with Google Cloud tools. It is essential for ML API data preparation as it provides real-world exercises on handling, cleaning, and structuring data for machine learning models.
Google Cloud ML APIs support various data types, including structured data (CSV, JSON, databases), unstructured data (text, images, audio, video), and streaming data from real-time sources.
You can collect data from public datasets, databases, or user-generated inputs and import it into Google Cloud using Cloud Storage, BigQuery, or Google Drive integration.
The main steps include:
Removing duplicate and missing data
Normalizing formats (text, images, or audio)
Converting data into ML-friendly formats (e.g., one-hot encoding for categorical variables)
Annotating and labeling data for supervised learning
Some key tools include:
Google Cloud Storage – For storing datasets
BigQuery – For analyzing and structuring large datasets
Google Cloud Dataflow – For batch and stream processing
Data Labeling Service – For annotating datasets for supervised learning
A common approach is the 80-10-10 rule:
80% for training (teaching the model)
10% for validation (tuning hyperparameters)
10% for testing (final evaluation)
Google Cloud provides a Data Labeling Service that allows you to manually or automatically label data for ML training. Third-party tools and Python-based libraries like LabelImg and SpaCy can also be used.
Yes! You can use Cloud Functions, Dataflow, and AI Platform Pipelines to automate data cleaning, transformation, and ingestion processes.
